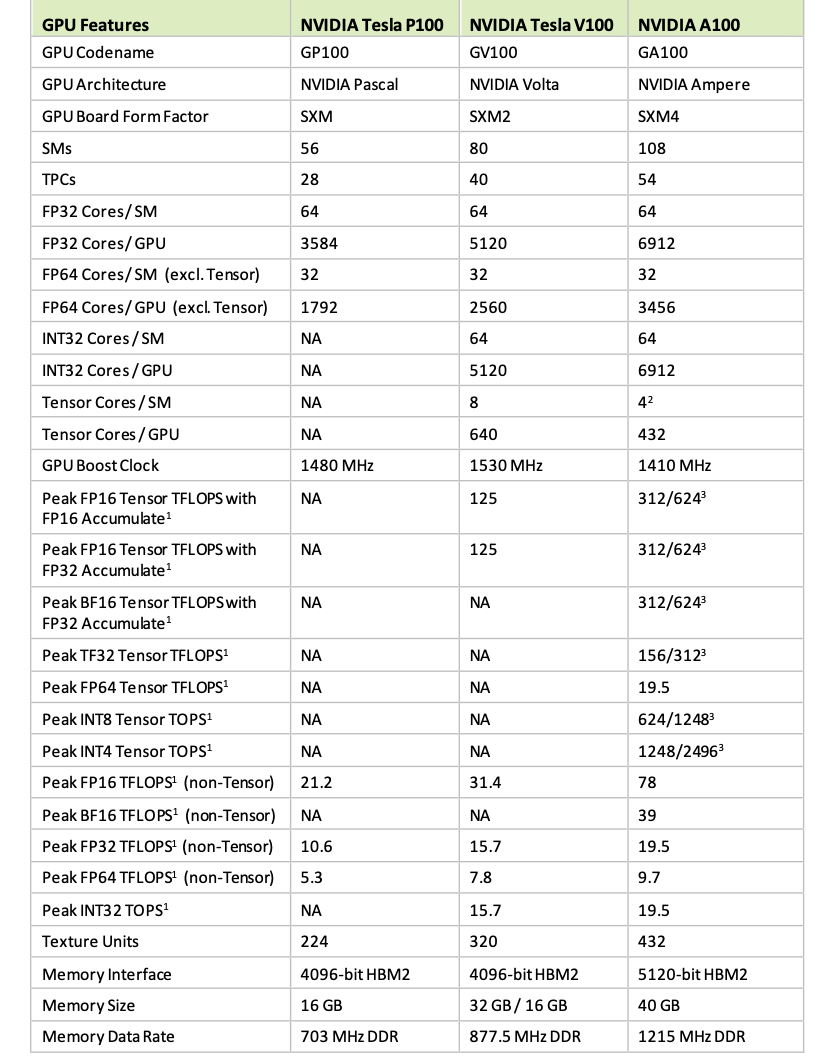
En 2017, Nvidia lançait le GPU Tesla V100 de génération Volta qui est devenu un standard de l’équipement de data-centers. Le fondeur récidive avec l’A100 Ampere dont les transistors sont gravés en 7 nm. Vingt fois plus performant que le V100, ce GPU sera très utile dans différents domaines de recherche s’appuyant sur l’Intelligence artificielle.

Les modèles d’IA gagnent en complexité. Leur entraînement requiert une puissance de calcul massive ainsi qu’une importante évolutivité.
L’IA est gourmande. Et surtout, l’apprentissage en profondeur (Deep Learning ou DL), l’une des sous-catégories de l’intelligence artificielle avec le Machine Learning (ou ML). Le DL est l’un des plus importants défis de l’informatique et le plus exigeant en puissance de calcul.
Pour réaliser de nouvelles découvertes scientifiques, les chercheurs ont en effet recours à des simulations avancées afin d’étudier des systèmes moléculaires complexes à des fins de recherche pharmaceutique, d’utiliser de nouveaux modèles physiques pour identifier de nouvelles sources d’énergie ou d’analyser de grands volumes de données atmosphériques pour mieux anticiper les phénomènes climatiques extrêmes.
C’est la raison pour laquelle, les fondeurs et autres entreprises spécialisées dans les processeurs développent des composants spécifiques. Dans ce domaine, Nvidia multiplie les innovations.
Son Tesla V100 était devenu une référence pour alimenter nombre d’applications de Deep Learning. Premier GPU basé sur l’architecture Ampère de Nvidia, le nouveau A100 présente de sérieux arguments pour devenir également une référence en la matière.
L’un des sauts technologiques clés de ce processeur A100 est le passage d’une gravure de transistors de 12 nm pour le V100 de 2017 à 7 nm, ce qui a permis à surface presque égale de plus que doubler le nombre de transistors (on passe de 815 mm² à 826 mm²).
Ce nouveau GPU possède 54 milliards de transistors et peut exécuter 5 pétaflops de performance, soit environ 20 fois plus que le GPU V100 de la génération précédente.
Selon Nvidia, « l’architecture Ampere optimise les performances de calcul en ouvrant la voie à de nouveaux niveaux de précision (TF32 et FP64). Cette innovation technologique accélère et simplifie l’adoption des applications d’IA et apporte toute la puissance des cœurs NVIDIA Tensor aux workflows de calcul haute performance ».
Le système A100 apporte une puissance de calcul sans précédent aux data centers. Pour optimiser l’utilisation des moteurs de calcul, le système est doté d’une bande passante très performante de 1,5 téraoctet par seconde (To/s), ce qui représente un gain de performance de 67 % par rapport à la génération précédente.

L’A100 n’est pas le plus grand processeur dédié à l’IA. Fabriqué par TSMC sur sa technologie à 16 nm, le Cerebras Wafer Scale Engine (entre les mains de Sean Lie
Chief Hardware Architect et cofondateur de la startup Cerebras) compte 1,2 trillion de transistors, 400 000 unités de traitement et 18 Go de mémoire cache
Pour ceux que cela intéresse, toutes les informations techniques sur l’A100 se trouvent ici, au milieu de quelque… 450 slides (pour cause de pandémie, la conférence était virtuelle) de la Linley Spring Processor Conference 2020, dont le thème central de cette année était justement l’IA.
A cette occasion, Nvidia a déclaré équiper huit des dix supercalculateurs les plus rapides au monde. Concernant le GPU A100, il est déjà intégré à des supercalculateurs ou à des serveurs hautes performances, comme le BullSequana X2415 d’Atos, l’ESC4000A-E10 d’Asus et le G292-Z40 de Gigabyte. Une cinquantaine d’intégrations sont prévues cette année. Les utilisateurs de Google Cloud peuvent aussi profiter de la puissance des GPU Ampere de NVIDIA pour leurs applications reposant sur l’IA.
L’arrivée de l’A100 confirme le dynamisme de Nvidia, comparé à Intel qui a eu du mal à se diversifier après avoir dominé pendant des décennies le marché des processeurs pour PC et serveurs.
Intel tente de reprendre la main sur le marché de l’IA. L’année dernière, il a acquis la start-up israélienne Habana Labs, pour 2 milliards de dollars, qui développe des accélérateurs d’apprentissage profond (ou Deep Learning) programmables pour les datacenters.
Toutefois, Nvidia reste encore loin d’égaler Intel. Des analystes s’attendent à ce que les revenus de Nvidia augmentent de 34 % au cours de son exercice fiscal actuel pour atteindre 14,6 milliards de dollars, tandis que les revenus d’Intel pour 2020 devraient augmenter de 2,5 % pour atteindre 73,8 milliards de dollars.

